Unité de Recherche INRIA Rhône-Alpes 655 avenue de l'Europe
F-38330 Montbonnot Saint-Martin
When editing Web pages, a user may desire to transform the documents as freely as with a word processor. But because Web documents must conform to a rigorous structure (defined by the HTML DTD), every transformation is not allowed and the editing system must perform some work to obtain valid HTML documents.
This paper presents a solution to the problem of transforming the document structure in a HTML editor. A tool based on a transformation language is described. Techniques that have been designed for general structured documents have been adapted to take into account the specific structure of the HTML DTD.
The increasing activity around the Web leads to the emergence of new tools. This paper focuses on tools for interactively creating and updating HTML documents. The ideas developed here are implemented in Tamaya [Quint95] , an authoring environment wired on the World Wide Web. Tamaya is a Web client that allows users not only to browse, but also to edit existing Web pages and to create new ones.
Web documents are described in a common representation called HTML (HyperText Markup Language). Although HTML markup is often used to describe the graphical aspect of documents, it has been designed to represent a document logical structure. The HTML DTD (Document Type Definition), expressed in SGML [ISO86] , specifies hierarchical dependencies between tagged elements. As a consequence, tags are not supposed to be inserted at arbitrary places in HTML documents, but their positions are constrained by the HTML DTD.
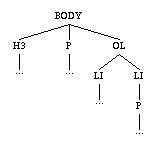
In order to handle structure in HTML documents, a document can be represented by a tree called an instance tree and each tagged region of a document is also an instance tree or a forest of trees. In this representation, each tag of the document is a node in the instance tree. The representation of nested tags are child nodes. Figure 1 shows an example of a HTML document and the corresponding instance tree.
<BODY>
<H3>...</H3>
<P>...</P>
<OL><LI>...
<LI>...
<P>...</P>
</OL>
</BODY>
Figure 1 - A HTML document and its instance tree
The next section discusses the issue of editing Web documents, section 3 identifies different restructuring needs and section 4 describes some approaches that have been taken in different areas where restructuring is necessary. The rest of the paper is devoted to the solution implemented in Tamaya for interactive structural transformations of HTML documents.
Most existing documents on the Web do not conform to the HTML DTD, but browsers are flexible enough to display invalid documents. However, incorrectly tagged documents can lead to different interpretations and prevent from further document processing, such as automatic extraction and filtering of information or different presentations of a document (using Cascading Style Sheet for instance [Lie95] ).
There are mainly three ways to produce Web documents:
It is very difficult for a human being to write by hand correct HTML documents, because of the complexity of the HTML syntax. Filters usually produce valid HTML documents, but users often need to modify them in order to obtain a final version. Therefore, among these three ways of document production, only authoring tools that provide structure and syntax checking can ensure the correctness of documents.
In Tamaya, checking is performed while the document is being edited. The user does not need to know the HTML language, as menus and dialogue boxes help users to create new elements; hypertext links can be added or modified very simply, by activating a command and clicking the target document. Editing is performed directly on formatted documents.
Structural constraints imposed by the HTML DTD is a limitation in interactively editing HTML documents. For example, the familiar command that allows a user to copy or cut a part of a document (the source) and to insert (or paste) it into another part (the target) may be refused because it would lead to an incorrect structure. For handling this command, an editor must take into account both the structure of source elements and the structure allowed in the target.
To allow a cut-and-paste operation to work when structures are different, source elements must be transformed to become consistent with the target structure. Usually, the user wants this transformation to be automatic when editing a document. In most cases, limitations to cut-and-paste due to structure differences are bothering. Sometimes, the user may want to indicate preferences when several transformations are possible or for complex transformations.
Two main classes of HTML document transformations may be identified:
The first class corresponds typically to the situation where the user wants to create a HTML document from raw text. Usually, the user starts from a flat document containing a sequence of paragraphs, and changes tags of each paragraph one after the other. This operation could be speeded up if the user could select a set of paragraphs and apply to them a more complex transformation. For example, a sequence of paragraphs can be transformed into a list in which each item contains a paragraph of the source structure; a DL (Definition List) structure can be filled up with source paragraphs alternatively in DT (Definition Term) and DD (Definition Data) elements.
The second class corresponds to the situation where the user decides to move some part of a document to another place (the common cut-and-paste operation) or to change the structure of a selected set of elements without moving them. These transformations are provided by the editor by the means of two sets of commands:
The methods for implementing restructuring operations depend on the differences between the source and the destination structures, not on the command itself. In most cases, several proposals can be presented to the user, depending on the source type. But the user may also want to express a specific transformation, and therefore a transformation language is needed.
Few studies have been made on the specific problem of document structure transformations. Some analyses of that problem can be found in [Akpotsui92] , [Arnon93] , [Furuta88] , [Feng93] and [Kuikka93] , but structured editing systems are not the only systems faced with problems of structure conversions; similar problems arise in other areas such as programming languages, structure-oriented programming environments (Gandalf [Garlan86] , Centaur [Borras88] , Synthesizer Generator [Reps89] ) and object-oriented databases [Skara87] . In most of these areas, type conversions are based on explicit specifications of the desired transformations [ISO95] . Synthesizer Generator [Reps89] uses "transformation declarations", SIMON [Feng93] is based on an extension of attributes grammars, Centaur is based on another extension of attributes grammars, natural semantics.
When synthesizing these structure transformations techniques [Keller 84] and applying them to HTML documents, three main methods can be identified. They can be applied alone or combined, depending on structural differences between source and target structure definition:
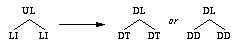
Explicit transformation: when the user wants to specify how some specific (or all) elements of the source must be transformed, explicit transformation rules are necessary. As an example a user may wish to transform an UL element into a DL, the first LI into a DT, and the second LI into a DD.
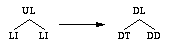
The aim of HTML is to represent a large diversity of documents. As a consequence, types defined in its DTD are general and can be used in various contexts. Thus, HTML documents usually have a flat structure (all headings are at the same level), but recursive types can produce deeper parts in documents (nested lists and directories). Due to this specific structure, a general tree transformation method is not relevant for HTML document transformations.
Furthermore, when the user wants to give a hierarchical structure to a flat document, the editor cannot do it automatically: hierarchies cannot be deduced from the sequence of tags of siblings elements. Explicit rules are required in this case.
This section describes the language-based conversion mechanisms used in Tamaya. The first part explains the motivations for defining a new language, then the expression of transformations is presented. Finally, the transformation process is described.
The goal of the transformation language is to express transformations that can't be automatically achieved. When composing a HTML document, the starting point is frequently a plain text document or/and several HTML fragments.
Like many languages for document structure transformation (DSSSL [ISO95] , Scrimshaw [Arnon93] ), the one presented here is based on tree pattern matching [Hoffman 82] to identify elements to be transformed, and replacement rules to specify the target types. The problem posed by existing languages is that the expression of patterns and transformations are complex and are not easily understandable by a human being. For instance, a language like DSSSL applies for any SGML document, and for that reason, it is too much complex and not well suited to HTML documents. A specific language is more appropriate and much simpler to implement.
The language described below has two original features:
Furthermore, an incremental definition of transformations is provided: the transformation system works on a set of predefined transformations. This set can be read from a file at initialization time and it can be dynamically completed by the user at any time. When a new transformation is introduced in the system, its conformance with the HTML DTD is checked and the pattern is parsed in order to produce an internal parenthesized string representation.
The language allows the specification of transformations to be applied to sets of elements that match a pattern. Each transformation is defined by:
The specification of a transformation is written as a source pattern between square brackets followed by a list of transformation rules between curly brackets:
Transformation ::= '[' Pattern ']' '{' RuleList '}'
Examples of patterns are:
These examples, informally given in English, are formally represented by pattern expressions. A pattern expression is an expression built with tags and operators:
Four operators available:
There might be several occurrences of a same tag in a pattern expression. Thus tag names should be renamed to avoid ambiguity if different rules are to be applied to different occurrences of the same tag in the pattern expression. The renaming of a tag is an association of a local name with an occurrence of a tag in the pattern (see the example (2) below). The local name and the tag name are separated by a colon.
Parentheses are used for grouping nodes on which the same operator must be applied (for instance, the operator +).
The definition of a pattern expression is :
Pattern ::= Forest | Forest '|' Pattern
Forest ::= Tree | Tree ',' Forest
Tree ::= Branch | Branch '.' Tree
Branch ::= Node | Node '+'
Node ::= TagName | LocalName ':' TagName |
'(' Pattern ')'
Here are some examples of pattern expressions and the structure they represent (see figures 3 and 4 ):
(1) (OL|UL).LI+
This pattern identifies a sequence of Items of an Ordered or Unnumbered List.
(2) H3,(SectParag:P|UL)+,(H4,SubSectParag:P+)+
This pattern identifies a H3 heading followed by a sequence of paragraphs and Unnumbered Lists, itself followed by a repetition of H4 followed by a sequence of Paragraphs. As the tag P appears twice in the pattern, it is renamed by two different names (SectParag and SubSectParag). This pattern is typically a part of the structure of a document organized in sections and subsections.
Once the pattern to be matched is defined, the transformation rules to be applied to elements matching the pattern are given between curly brackets.
A rule has two parts:
Both parts are separated by the symbol '->' and a rule is terminated by a semicolon.
The target tag list is defined by a list of tags separated by dots. It gives the position where new elements have to be inserted. This position is given relatively to the rightmost branch of the target instance tree being generated. The first node in the list that does not yet exist involves the creation of a branch of new elements.
A special separator ':' may appear once in the list to specify when a new branch must be generated in the target tree. Different positions of this separator in the target tag list can induce different results, as shown in figure 2 .
transformation 1: [ P+ ] { P -> UL:LI.P ; }
transformation 2: [ P+ ] { P -> UL.LI:P ; }
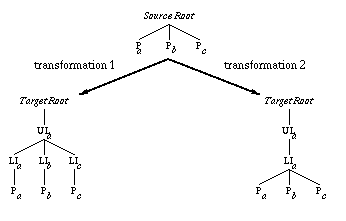
Figure 2 - Two transformations of the same source
If the separator ':' is placed at the head of the target tag list, a new instance tree is created as the last child of the target root. This feature is useful to express transformations that suppress hierarchical levels such as the following Figure 3 based on pattern (1):
[ (OL|UL).LI+ ]
{ LI -> :P ; }
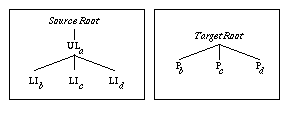
Figure 3 - A transformation that suppresses levels
Here is a set of rules for pattern (2) which adds new hierarchical levels:
[ H3,(SectParag:P|UL)+,(H4,SubSectParag:P+)+ ]
{ H3 -> :DL.DT ;
SectParag -> DL.DD:P ;
H4 -> DL.DD:DL.DT ;
SubSectParag -> DL.DD.DL.DD:P ; }
Figure 4 shows the tree of a matched source instance and the tree of the target built when applying the rules to the source. In the source instance tree, each matched node is denoted by a italic lowercase letter, the corresponding nodes of the target are denoted by the same letter.
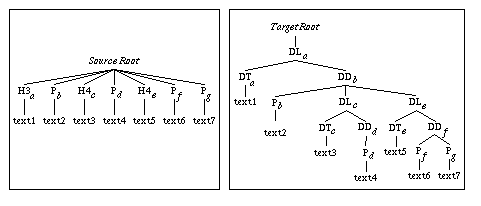
Figure 4 - A transformation that adds levels
Each element of type H3 (a) requests the creation of a DL element with a DT child. The first element SectParag following a H3 (b) involves the creation of a DD element as the last child of the DL previously created. Every next SubSectParag (g) is placed as a sibling of the previous one. Every H4 (c and e) involves the creation of a new DL.
It is not necessary to give rules for every element that matches the pattern (in the example above, no rule is given for UL). The transformation of these elements depends on whether they are empty or not and on their structural context (see below).
The definition of the transformation rules list is:
RuleList ::= Rule | Rule RuleList Rule ::= Name '->' DestType ';' DestType ::= PlaceNode ':' NewNodes | ':' NewNodes PlaceNode ::= NodeList NewNodes ::= NodeList NodeList ::= TagName | TagName '.' NodeList
When a structuring command is invoked by a user (cut-and-paste or change type for example), patterns are checked against the current selection.
A source tag string representing the structure of a selected region is first constructed. In the source tag string, the content of selected elements is ignored; only tags and their relative positions are represented. As an example, here is a part of a HTML document:
<UL> <LI> This is a list item <LI> This is another list item </UL> <P> This is a paragraph
The corresponding source tag string is:
UL{LI,LI},P
Then, the source tag string is compared with patterns from transformation expressions, using a stack based algorithm [Kilpe92] . If more than one pattern matches, the set of matched patterns is presented to the user, for choosing the wished transformation. Once a transformation has been chosen by the user, the source instance trees corresponding to matched elements are traversed and target instance trees are produced according to the transformation rules associated with the pattern.
As stated above, only a subset of matched tags is usually present in the left side of transformation rules. The transformation of a source instance node is different whether its related tag participates to the left side of a transformation rule or not. In the first case, an explicit transformation is specified by the rule; in the latter case, an implicit transformation occurs.
Figure 5 shows the transformation of a DL containing a DT and a DD with paragraphs and ordered lists. The DT is changed into a H3, and the content of the DD is changed into a UL. Each component of the DD involves the creation of a LI element. It is not necessary to provide an explicit transformation rule for each node of the pattern (indeed, only two rules are needed), thanks to the algorithm described below.
Transformation definition:
[DL.(DT,DD.(P|OL)+)+]
{ DT -> :H3;
P -> UL:LI.P; }
Source and destination instance trees:
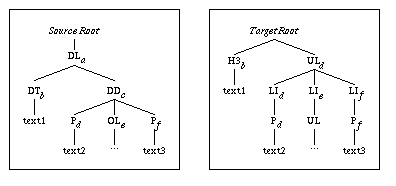
Figure 5 - A complex transformation
If a matched tag appears in the left side of a rule, the rightmost branch of the target instance tree is traversed until it is consistent with the place defined by the rule. If the deepest place node cannot be reached, missing nodes are inserted in the target instance tree (UL (d) node in figure 5 ).
Once the deepest place node is identified, new nodes are created in the target instance tree. In the example of figure 5 , a LI and a P are created in the target each time a P is transformed (d and f). The way to create the deepest new node depends on the descendants of the source instance node. The strategy is different whether a matched node is present or not in these descendants.
Elements in the source instance that match the pattern but have no explicit transformation rules must be generated in the target tree. The information carried by these elements must not be lost by the transformation (this is usually a basic requirement to such editing operation). The question is how and where these nodes are moved in the target tree.
Like in explicit transformations, the solution chosen depends on the descendants of the current source node:
The last example (figure 5 ) shows that automatic restructuring may be used to manage transformation of subtrees. The source OL element has been copied in a LI element (e). As those structures are different, an automatic type conversion of the OL element has been performed. The automatic type converter is based on structural comparison of the structures of both the source element type and the destination type. The details of automatic conversion can be found in [Roisin94] ; only the basic principle is given here.
When an automatic conversion of an element into another type is needed, both source and target structure tree representations are built. Then, these trees are matched to associate each source element with a target type. Once every source element is associated, the source instance tree is traversed and target elements are generated according to the associations found, the target leaves being filled with the content of source leaves.
Several approaches to type transformation in HTML documents have been presented in this paper. The needs in the process of composing and editing Web documents and the methods that could fulfill theses needs have been identified.
The language presented here is not intended to be expressive enough to describe all possible transformations in structured documents, but it permits the specification of most transformations users need when editing HTML pages.
As opposed to most transformation systems which require an extensive definition for transformation of all source elements, the language defined here provides for the expression of contextual transformations by giving as few information as possible to the system. It uses both contextual information and automatic restructuring to deduce implicit transformations.
This transformation language has been conceived for improving structure manipulation in the Tamaya editor. But implementing the language is not enough for an interactive WYSIWYG editor. A specific extension of the user interface has now to be designed for allowing users to specify transformations and to modify existing ones.
Thanks are due to Vincent Quint and Iréne Vatton, which are the principal designers of Tamaya, the editor we are using to implement the ideas developped in this paper.